


$0.14 per million input tokens. That's what DeepSeek is charging for V4-Flash — the model they're positioning as their agentic coding workhorse. GPT-5.5 costs $5.00 per million input tokens. Claude Opus 4.7 costs the same. For teams running output-heavy agent loops, that's not a marginal difference — it's a different product economics conversation entirely. DeepSeek V4 Preview landed on April 24, 2026 with two new API models, 1M context as the default floor, and open weights under MIT. The "Preview" label carries real operational meaning that most coverage is glossing over. Here's what actually changed, what the open-source SOTA claims hold up on, and what still needs your own verification.
The API Change in Plain English
Keep the same base URL
Nothing changes on the infrastructure side. Your base URL, authentication, and request format all stay the same. DeepSeek's official V4 release note is explicit: "Keep base_url, just update model to deepseek-v4-pro or deepseek-v4-flash." Both new models support the OpenAI ChatCompletions API format and the Anthropic Messages API format — whichever your current integration uses continues to work.

Switch to deepseek-v4-pro or deepseek-v4-flash
The only required code change is the model parameter. The two new model IDs are:
# Before (legacy aliases — retire July 24, 2026)
model = "deepseek-chat" # maps to V4-Flash non-thinking
model = "deepseek-reasoner" # maps to V4-Flash thinking
# After (explicit V4 model IDs)
model = "deepseek-v4-flash" # fast, cost-efficient
model = "deepseek-v4-pro" # stronger reasoning, higher costBoth V4 models support Thinking and Non-Thinking modes natively, plus a Max reasoning mode. The old alias-to-model mapping (deepseek-chat → non-thinking, deepseek-reasoner → thinking) is preserved in the legacy routing during the transition window, but migrating to explicit model IDs gives you direct access to all three reasoning effort modes rather than relying on alias convention.
DeepSeek V4 Pricing Structure
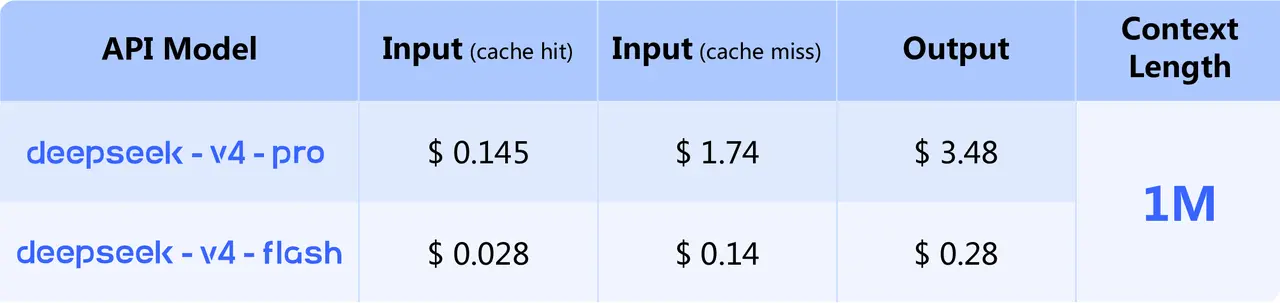
All prices sourced from the official DeepSeek pricing page as of April 28, 2026.
| Model | Input (per 1M tokens) | Output (per 1M tokens) |
|---|---|---|
| deepseek-v4-flash | $0.14 | $0.28 |
| deepseek-v4-pro | $1.74 | $3.48 |
Context window for both: 1M tokens. Maximum output: 384K tokens.
DeepSeek has not published pricing for the Max reasoning effort modes separately. For cache hit input tokens, DeepSeek's historical pattern has been a significant discount — check the current pricing page for any cache pricing tiers that apply to V4.
V4-Pro vs V4-Flash cost profile
The 12× input price difference between Flash and Pro is large enough to change product economics on high-volume workloads:
| Monthly output volume | V4-Flash cost | V4-Pro cost | GPT-5.5 cost |
|---|---|---|---|
| 10M tokens | $2.80 | $34.80 | $300.00 |
| 100M tokens | $28.00 | $348.00 | $3,000.00 |
| 1B tokens | $280.00 | $3,480.00 | $30,000.00 |
V4-Pro at $3.48/M output is roughly 8–9× cheaper than GPT-5.5 ($30/M) and Claude Opus 4.7 ($25/M); V4-Flash at $0.28/M is roughly 90–100× cheaper. Whether the quality tradeoff is acceptable for your specific workload is the variable — see DeepSeek V4 Preview for Coding: What Actually Changed for capability detail.
What "cost-effective 1M context" means in practice
V4's 1M context window is the default floor for all V4 API calls, not a premium tier. V3.2 had a 128K context limit; V4 expands that 8× with no per-call surcharge. The architecture improvement (Hybrid Attention combining CSA and HCA) makes long-context calls genuinely cheaper per token: at 1M token prompts, V4-Pro uses 27% of the single-token inference FLOPs compared to V3.2.
Cost implication: teams running RAG pipelines specifically to work around the 128K context limit should re-evaluate whether that infrastructure is still necessary. Loading a full codebase at 1M tokens costs $0.14 per call on Flash — a very different calculation than routing through a chunking pipeline with multiple smaller calls.
Migration from deepseek-chat and deepseek-reasoner
Retirement timeline to July 24, 2026
| Legacy alias | Currently routes to | Retire date |
|---|---|---|
| deepseek-chat | V4-Flash, Non-Thinking mode | July 24, 2026, 15:59 UTC |
| deepseek-reasoner | V4-Flash, Thinking mode | July 24, 2026, 15:59 UTC |
After July 24, 15:59 UTC, any call using either legacy alias returns an error — no silent fallback, no grace period beyond that timestamp. Three months is a comfortable window if you start now. It's not comfortable if you wait until July.
Current routing behavior and why it matters
Since April 24, legacy aliases have routed to V4-Flash, not V3.2. Two implications:
If your system has been stable on deepseek-chat** since April 24**, your effective migration to V4-Flash non-thinking mode is already underway. If you haven't seen regressions, that's a positive signal for your workloads — you may have less behavioral delta to manage than expected.
On pricing: calls through deepseek-chat since April 24 have been billed at V4-Flash rates ($0.14/$0.28), not V3.2 rates. If you haven't checked your API cost dashboard since the launch, verify this against your billing data — the rate may have changed without you explicitly migrating.
What Teams Should Update First
Model IDs in production configs
Audit every location in your codebase and configuration files where a DeepSeek model name is set:
# Find all legacy alias references
grep -r "deepseek-chat\|deepseek-reasoner" . \
--include="*.py" --include="*.ts" --include="*.js" \
--include="*.yaml" --include="*.env" --include="*.json"For each occurrence, decide on the replacement:
- V4-Flash for: chat interfaces, summarization, document Q&A, simple coding completions, latency-sensitive or cost-sensitive routes
- V4-Pro for: complex multi-step reasoning, deep agentic coding, long-context analysis requiring the full parameter count
One non-obvious case: if your codebase uses deepseek-reasoner, do not automatically replace it with deepseek-v4-pro. The legacy alias routes to V4-Flash thinking mode, so the equivalent explicit migration is deepseek-v4-flash with thinking enabled — unless your evaluation shows you actually need V4-Pro's additional capacity for that workload.
Cost monitoring and prompt budgets
V4's 384K maximum output token limit is higher than V3.2's limits. Applications that don't set explicit max_tokens can now generate substantially more output per call than they did on V3.2. Set it explicitly on every call:
response = client.chat.completions.create(
model="deepseek-v4-flash",
max_tokens=4096, # set explicitly; don't rely on defaults
messages=[...],
)At V4-Flash's $0.28/M output, runaway token generation is inexpensive in absolute terms. At V4-Pro's $3.48/M, uncontrolled output spend on high-volume workloads adds up quickly. Set limits regardless of which model you use.
Tooling compatibility with OpenAI and Anthropic-style APIs
V4 supports both the OpenAI ChatCompletions API and the Anthropic Messages API format. If your current integration uses either format against DeepSeek's endpoint, it continues to work — no request format changes needed beyond the model parameter.
For tools that auto-detect model capabilities (Continue.dev, VS Code extensions, Cursor), verify V4 model IDs appear in the tool's model list or add them manually. Older tooling versions may have V3.2's 128K context limit cached in model metadata; you may need to explicitly configure the 1M context window in those integrations.
Common Migration Risks
Hidden fallback assumptions
Some codebases include retry or fallback logic that references legacy model aliases. Code that says "if the primary model fails, retry with deepseek-chat" will break after July 24. Search for legacy alias strings in your retry logic, error handlers, and fallback configuration — not just the primary API call paths.
Also check: API gateway route tables, load balancer configurations, model registry definitions, and any CI/CD pipeline steps that reference a DeepSeek model by name.
Token cost surprises at 1M context
The 1M context window doesn't mean every call should use 1M tokens — it means the ceiling is there when you need it. Model the input cost explicitly before routing large-context calls at scale:
# Cost per call at full 1M token input
V4-Flash: 1,000,000 × $0.14/1,000,000 = $0.14 per call
V4-Pro: 1,000,000 × $1.74/1,000,000 = $1.74 per callAt V4-Flash rates, 1M-token inputs at moderate volume are economically viable. At V4-Pro rates, loading 1M tokens per call at high volume costs $1,740/1,000 calls — worth modeling before you route all long-context work to Pro by default.
If DeepSeek publishes cache hit pricing for V4 (their historical pattern for V3 applied a substantial cache discount), workloads that reuse the same long system prompt or document across many calls will see materially lower effective input costs. Check the official pricing page for current cache tier details before finalizing cost projections on cache-heavy workloads.
FAQ
Do I need to change my base URL?
No. Base URL, authentication, and request format are all unchanged. Only the model parameter needs to update. Full API documentation at api-docs.deepseek.com.
When will deepseek-chat stop working?
July 24, 2026, 15:59 UTC. After that timestamp, calls using deepseek-chat or deepseek-reasoner will error — no grace period, no silent fallback. The three-month window from the April 24 launch is enough time to migrate safely if you start regression testing now.
Which model is better for cost-sensitive coding agents?
Start with V4-Flash. DeepSeek's own positioning confirms it matches V4-Pro on simpler agent tasks and costs 12× less. Only escalate to V4-Pro when your evaluation shows Flash quality is insufficient for a specific task type. For most coding agent workflows — repository analysis, code generation, moderate refactoring — Flash is the right first route to benchmark.
Conclusion
The migration is a one-line code change per API call. The risk is in the deadline, not the complexity: deepseek-chat and deepseek-reasoner stop working at July 24, 2026, 15:59 UTC, with no fallback. Run the alias search across your codebase today, set up V4-Flash as a parallel test route, and let regression testing run through May and June so you have time to catch any behavioral differences before the deadline. The pricing improvement at V4 rates makes the migration worth doing well before you're forced to.
Related Reading
