


It's Friday morning, your Codex session has been running for 40 minutes on a multi-file refactor, and the model just finished without you babysitting a single tool call. That's the GPT-5.5 for coding pitch in one sentence — and it's the part I've been stress-testing all week against the workloads my own team actually runs.
I review AI coding tools by putting them on real production work, not curated demos. OpenAI shipped GPT-5.5 on April 23, 2026, then quietly opened the API the next day. The capability story is real. The economics are tighter than the launch announcement frames them. This piece is what I'd actually tell a Tech Lead asking whether to migrate from GPT-5.4 today, drawing only on OpenAI's official materials so you can verify everything I claim.
What GPT-5.5 Is for Developers

OpenAI's "real work" positioning
The pitch in OpenAI's launch announcement is unusually narrow for a frontier release. From the official "Introducing GPT-5.5" page:
"Instead of carefully managing every step, you can give GPT-5.5 a messy, multi-part task and trust it to plan, use tools, check its work, navigate through ambiguity, and keep going."
The language signals the design intent: less prompt engineering, more autonomous task completion. Greg Brockman framed this on the press call as "a real step forward towards the kind of computing that we expect in the future." OpenAI explicitly identifies four areas where the gains are strongest: agentic coding, computer use, knowledge work, and early scientific research.
Why coding is a core launch theme
OpenAI's announcement page calls GPT-5.5 "our strongest agentic coding model to date." The model's coding strengths are framed as dependent on three behaviors that distinguish it from GPT-5.4:
- Holding context across large systems — multi-file reasoning over real codebases
- Reasoning through ambiguous failures — recovering from tool errors, not just visible code bugs
- Checking its own work — internal verification before declaring tasks complete
OpenAI's internal data point: 85% of the company uses Codex weekly across functions including software engineering, finance, communications, marketing, data science, and product management. Whatever weight you give to in-house adoption claims, it's the lens through which the model was tuned.
What GPT-5.5 Officially Improves
Agentic coding and tool use
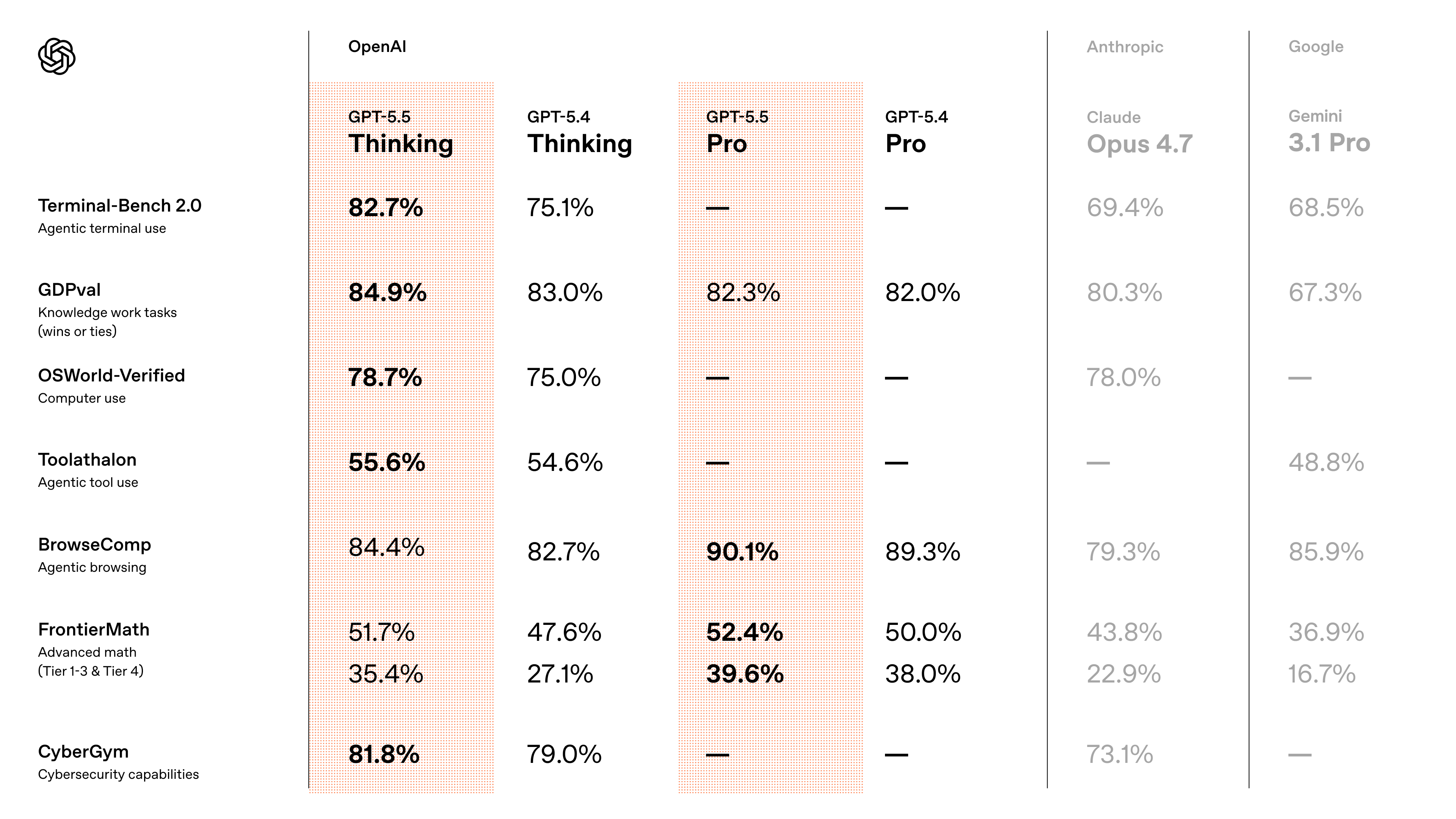
OpenAI publishes three coding-specific benchmarks where GPT-5.5 advances over GPT-5.4:
| Benchmark | GPT-5.5 | GPT-5.4 | What it measures |
|---|---|---|---|
| Terminal-Bench 2.0 | 82.70% | 75.10% | Complex command-line workflows requiring planning, iteration, and tool coordination |
| SWE-Bench Pro | 58.60% | (lower) | Real-world GitHub issue resolution, single-pass |
| Expert-SWE (internal) | Outperforms 5.4 | — | Long-horizon coding tasks; ~20-hour median estimated human completion time |
All three numbers are OpenAI's own benchmarks. Important caveat: on SWE-Bench Pro, Claude Opus 4.7 scores higher at 64.3%. GPT-5.5 leads on Terminal-Bench 2.0 and OpenAI-internal evaluations; Opus 4.7 leads on SWE-Bench Pro. Don't conflate "strongest agentic coding" with "best at every coding benchmark."
OpenAI also claims GPT-5.5 uses fewer tokens than GPT-5.4 to complete the same Codex tasks, with same-tier latency. The token efficiency claim is independently relevant for cost: doubled per-token pricing is partially offset by lower token consumption per task.
Computer use and multi-step task execution
The OSWorld-Verified score — measuring autonomous operation in real-world computer environments — moved from 75.0% (GPT-5.4) to 78.7% (GPT-5.5). On Tau2-bench Telecom, which tests complex customer service workflows without prompt tuning, GPT-5.5 reaches 98.0% (up from 92.8%). These are OpenAI's reported numbers.
For coding agents that interact with browsers, IDEs, or GUIs as part of a workflow, the computer-use improvement is the most practically distinctive claim. The framing "messy, multi-part tasks" is specifically a computer-use claim — and computer-use behavior is where benchmark numbers and production behavior diverge most. Treat the OSWorld score as a directional signal, not a guarantee on your specific workload.
Less guidance, more autonomous completion
The behavioral claim from OpenAI's own materials: "much more it can do with less guidance" (Brockman, press briefing). This translates to specific behaviors developers can observe:
- The model now supports a
xhighreasoning effort level (alongsidenone,low,medium,high) - It checks its own work before declaring tasks complete — fewer "I'm done" reports that turn out to be wrong
- It plans multi-step workflows rather than waiting for step-by-step prompting
If your current GPT-5.4 agent loop includes a separate "ask the model to verify" step, GPT-5.5 likely makes that step redundant. The internal verification is doing the same work.
What Developers Can Actually Use Today
The rollout sequence matters because it changed quickly:
ChatGPT availability
GPT-5.5 Thinking is available in ChatGPT for Plus, Pro, Business, and Enterprise users. GPT-5.5 Pro is limited to Pro, Business, and Enterprise tiers. Free-plan users do not currently have GPT-5.5 access.
Codex rollout
In Codex, GPT-5.5 spans Plus, Pro, Business, Enterprise, Edu, and Go plans. Context window in Codex is 400K tokens — meaningfully smaller than the API's 1M, but more than sufficient for most agentic coding workflows. Codex tasks running on GPT-5.5 use fewer tokens than equivalent GPT-5.4 tasks per OpenAI's data.
API availability (as of April 24, 2026)

GPT-5.5 and GPT-5.5 Pro are now both available through OpenAI's Responses and Chat Completions APIs. The model IDs are gpt-5.5 and gpt-5.5-pro. From the official API model documentation:
- Context window: 1M tokens (up to 922K input + 128K output)
- Reasoning effort levels:
none,low,medium(default),high,xhigh - Pricing: $5.00/M input, $30.00/M output (standard tier per the OpenAI pricing page)
- GPT-5.5 Pro pricing: $30.00/M input, $180.00/M output
- For prompts >272K input tokens, pricing scales to 2× input and 1.5× output for the full session
- Regional processing (data residency) endpoints add 10% uplift
The price doubled vs. GPT-5.4. GPT-5.4 was $2.50/$15; GPT-5.5 is $5/$30. OpenAI's framing is that token efficiency partially offsets this — independent benchmarking by Artificial Analysis put effective API costs about 20% higher than GPT-5.4, not 100% higher, when accounting for fewer tokens used per task. Verify on your own workload before committing.
Batch API and Flex pricing are 50% off standard rates. Priority processing is approximately 2.5× standard rates with faster guaranteed response times.
Where GPT-5.5 Looks Most Useful
Long tool chains
The model is built for workflows where an agent calls tools 30, 50, 100 times before completing a task. Terminal-Bench 2.0 specifically measures this — the 82.7% score on tasks involving planning, iteration, and tool coordination is the data point most directly relevant to long-running agent workflows.
If your agent loop currently fails at the 20–30 tool-call mark with state drift or hallucinated next steps, GPT-5.5's improvements target exactly that failure mode. If your workflow is short tool chains where GPT-5.4 already works reliably, the upgrade case is weaker.
Messy multi-part coding tasks
OpenAI's "messy, multi-part task" framing is specific. The implication: tasks that don't decompose cleanly into independent subtasks, that involve ambiguous requirements, that require recovery from intermediate failures. Examples that match this profile:
- Migrating an unfamiliar codebase from one framework to another, where the right path emerges from reading the code
- Debugging cascading failures where the visible error is downstream of the root cause
- Refactoring across multiple services where the design constraints aren't fully specified upfront
For well-scoped tasks with clear acceptance criteria, GPT-5.5's edge over GPT-5.4 is smaller. The model's strengths emerge when the task itself is ambiguous.
Research plus implementation workflows
OpenAI's launch material highlights early scientific research as a frontier where GPT-5.5 shows meaningful gains. For coding contexts, this maps to workflows where a developer needs to: research a problem domain (read papers, parse documentation), design an implementation approach, and write the code. The continuity across phases is what GPT-5.5 is designed to handle.
This is also where the 1M context window becomes useful in practice. Loading a research paper, a codebase, and a problem specification into a single context lets the model maintain coherence across the research-to-implementation transition without context fragmentation.
Known Limits and Open Questions
What still needs independent validation
OpenAI's reported benchmarks are vendor-reported. The independent benchmarks at launch are limited:
- Artificial Analysis rated GPT-5.5 as the top model overall by a slim margin over Claude and Gemini, but flagged a notable weakness on hallucinations. Their effective-cost analysis puts GPT-5.5 roughly 20% more expensive per task than GPT-5.4, not 100%.
- SWE-Bench Pro independent comparison confirms GPT-5.5 (58.6%) trails Claude Opus 4.7 (64.3%) — a meaningful gap on real-world GitHub issue resolution.
- Long-horizon performance on Expert-SWE is OpenAI's internal benchmark; no third-party replication exists at this writing.
The capability framing is real but the specific magnitudes need validation against your own workload before accepting the launch numbers as production guidance.
Pricing trajectory
GPT-5.5's per-token price is double GPT-5.4's. OpenAI has historically reduced Pro-tier pricing within 3–6 months of release on previous generations, but no public commitment exists for GPT-5.5. For long-horizon budgeting, don't assume today's $5/$30 is permanent — but also don't assume it will drop. Plan against current pricing.
Codex vs API token economics
If your monthly output token volume exceeds approximately 4M tokens, the math may favor a Pro ChatGPT plan plus Codex CLI usage over pay-as-you-go API billing — provided your workload fits inside the Codex 400K context window. For larger context requirements, the API at standard pricing is necessary. For highly variable workloads, Batch and Flex tiers (50% off standard) bring effective costs closer to GPT-5.4 levels.
Safeguards on API access
OpenAI explicitly noted that "API serving requires different safeguards" and updated the system card on April 24 to describe these. For dual-use or agentic workloads (cybersecurity research, content moderation systems, autonomous browsing), test refusal behavior on your specific use cases rather than assuming parity with GPT-5.4 behavior.
FAQ
Is GPT-5.5 available in the API?
Yes, as of April 24, 2026. Both gpt-5.5 and gpt-5.5-pro are available through the Responses API and Chat Completions API. Standard tier pricing is $5/M input, $30/M output; GPT-5.5 Pro is $30/M input, $180/M output. The 1M context window is available without long-context premiums for prompts under 272K input tokens.
Is GPT-5.5 mainly for coding?
Coding is a core launch theme but not the only one. OpenAI positions four areas as primary: agentic coding, computer use, knowledge work, and early scientific research. The benchmarks show strongest gains on Terminal-Bench 2.0 (coding) and Tau2-bench Telecom (customer service workflows). For coding specifically, the model leads on tool-coordination tasks but trails Claude Opus 4.7 on SWE-Bench Pro.
How is GPT-5.5 different from GPT-5?
The model is positioned as a step beyond GPT-5.4 (which itself shipped in early March 2026) with stronger autonomous task completion. Specific differences:
- Higher scores on Terminal-Bench 2.0 (82.7% vs 75.1%), OSWorld-Verified (78.7% vs 75.0%), and Tau2-bench Telecom (98.0% vs 92.8%)
- New
xhighreasoning effort level - Token consumption per task is lower per OpenAI's data
- Per-token API price doubled vs GPT-5.4 ($5/$30 vs $2.50/$15)
- 1M context window matches GPT-5.4's 1M
- Stronger agentic coding behavior — "less guidance, more autonomous completion"
The version numbers conceal the cadence: GPT-5 launched August 2025, GPT-5.4 in early March 2026, GPT-5.5 on April 23, 2026. Six weeks between 5.4 and 5.5 is unusually fast and reflects competitive pressure rather than a planned release schedule.
Conclusion
GPT-5.5 for coding is a real improvement on GPT-5.4 in specific dimensions — agentic tool coordination, computer use, multi-step task completion — at twice the per-token API price. The capability framing is consistent with OpenAI's strategic direction toward autonomous AI for "real work," and the rollout to ChatGPT, Codex, and the API within 24 hours of each other is operationally aggressive.
The honest assessment: if your coding workflows are bottlenecked by long tool chains, ambiguous multi-part tasks, or computer-use integration, GPT-5.5 is worth testing. If your workflows are well-scoped and GPT-5.4 already works reliably, the upgrade case is weaker until OpenAI's pricing trajectory clarifies. For SWE-Bench-Pro-style real GitHub issue resolution, Claude Opus 4.7 still leads — model selection should reflect the specific workload, not the most recent launch.
The capability story is real. The economics are tighter than the launch announcement frames them. Test on your own workload before migration, not on the launch benchmarks.
Related Reading
- Claude Opus 4.7 vs 4.6: Agentic Coding Comparison
- Kimi K2.6 vs Claude Opus 4.6 vs GPT-5.4: Agentic Coding Benchmarks
- Claude Opus 4.7 for Coding Agents: xhigh, /ultrareview & Task Budgets
- Agentic Engineering Patterns: Real Workflows for Dev Teams in 2026
- Harness Engineering in Practice: Build AI Coding Workflows That Scale
